
データ基盤の複雑化は、多くの開発現場で共通の課題となっています。「BIレポートの数値が合わない」という問い合わせを受け、原因調査のために複数のETLジョブのログやSQLを半日かけて手動で追跡します。「このテーブルのカラム定義を変更したい」という簡単な改修依頼に対し、どこまで影響が出るか分からず、膨大な影響範囲の調査に…。結果として、データ基盤の運用保守、いわゆる“火消し”対応と“データ整備”に工数の大半が奪われ、本質的なデータ活用が進まないことが発生します。
このような「データのブラックボックス化」は、担当エンジニアの負担を増大させるだけでなく、企業のデータ活用を停滞させる大きな要因です。
この深刻な課題を解決する鍵が、本記事のテーマである「データリネージュ(Data Lineage)」です。データリネージュは、直訳すると「データの血統」を意味し、データの流れを可視化する技術です。
本記事では、データリネージュの正確な定義から、それが「なぜ」現場の課題を解決できるのか、そして「どのように(How)」導入するのか、AWS、GCP、Azureの主要クラウドサービスやdbt、Tableauといった具体的なツールを用いた実現方法まで、データ基盤の運用に責任を持つ技術者向けに徹底的に解説します。
データリネージュとは「データの移動経路を記した地図」
先ほど、データリネージュは、データの血統を意味するものといいましたが、もう少し具体的にいうと、データがどこで生まれ、どのような経路で、どこへ向かうのか、その「移動の軌跡」を可視化したものです。
データリネージュの正確な定義:データの「発生源」から「行き先」まで
データリネージュは、データのライフサイクル全体を追跡します。
- 発生源(Source):
データが最初にシステムに取り込まれた場所(例:基幹システムのデータベース、S3に置かれたCSVファイル)。 - 変換(Transformation):
データが加工、集計、結合された処理(例:ETLジョブ、SQLクエリ、データウェアハウスとしてのテーブルなど)。 - 行き先(Destination):
最終的にデータが利用される場所(例:データマートとしてのテーブル、BIダッシュボード、機械学習に活用など)。
この一連の流れを線で結び、データの依存関係を「地図」のように可視化することで、複雑なデータパイプラインの全体像を俯瞰的に把握できるようになります。
なぜ今、データリネージュが「必須」の技術とされているのか

データリネージュという概念自体は新しいものではありませんが、近年その重要性が急速に高まっています。
- データ量の爆発的な増加と複雑化:
クラウド、IoT、SaaSの普及により、データソースが多様化・分散化しました。これにより、データの流れが指数関数的に複雑になり、手作業での追跡が物理的に不可能になっています。 - データ活用の高度化:
AI/機械学習や高度なビジネス分析において、インプットとなるデータの「質」と「信頼性」が、分析結果の質を直接左右します。データの出所が不明瞭・指標の算出定義がブラックボックスなままでは、分析結果を信頼できず、ビジネス上の意思決定に利用できません。 - 規制コンプライアンスの強化:
GDPR(EU一般データ保護規則)やHIPAA(医療保険の相互運用性と説明責任に関する法律)など、データの取り扱いに関する法規制が世界的に強化されています1。これにより、企業は「どのデータがどこにあり、どう使われているか」を証明する客観的な証跡(監査証跡)を保持することが法的に求められています。また、個人情報データが流出した際に、早急に原因を特定するためには、どこに何のデータがあるのか、誰が閲覧していたかログなどが蓄積されている必要があります。
データリネージュによる、データ運用・保守の最適化を目指す
データリネージュを導入する最大のメリットは、データ基盤の運用担当者が直面する2大工数、すなわち「障害時の原因特定」と「改修時の影響範囲特定」を効率化できる点や「データ活用の推進」の最適化にあります。
【課題1】障害時の原因特定の高速化
「BIレポートの数値が、昨日のバッチ実行後から、ある数値が合わなくなりました」
このような障害発生時、従来は担当者が経験と勘を頼りに、関連する無数のETLジョブ設定やSQLクエリログを一つひとつ手動で確認し、原因を特定していました。データリネージュが整備されていれば、このプロセスは根本から変わります。
- 流れ:
まず、問題が発生している「BIレポート」を起点にします。 - 追跡:
リネージュの「地図」を上流(Upstream)に向かって遡ります。 - 特定:
レポートが参照しているデータマート、そのデータマートを作成している中間テーブル、さらにその上流のETLジョブ…と依存関係をたどることで、どの変換処理(Transformation)でデータに異常が混入したかを即座に特定できます。
手動で半日かかっていた「火消し」のための原因調査が、数分で完了する可能性を秘めています。
【課題2】改修時の影響範囲の特定の自動化
「基幹システムの仕様変更に伴い、DWHのあるテーブルのカラムAの定義を変更します」
このような改修時、最大の恐怖は「影響範囲の特定漏れ」です。カラムAを参照している別のETLジョブや、その先のBIレポートを見落としたまま改修を実行すると、予期せぬ障害を引き起こします。
データリネージュは、この「影響範囲の特定(Impact Analysis)」を自動化します。
- 起点:
変更対象の「テーブルのカラムA」を起点にします。 - 追跡:
リネージュの「地図」を下流(Downstream)に向かってたどります。 - 把握:
カラムAに依存している全てのデータマート、ETLジョブ、BIレポート、ダッシュボードをリストアップします。
これにより、設計書が古くても、担当者の記憶に頼らなくても、客観的なデータに基づいて、正確な影響範囲を把握できます。これにより、改修の「見積もり工数」と影響範囲による「心理的安全性」が大幅に改善されます。
【課題3】データガバナンスとコンプライアンス対応
データリネージュは、技術的な課題だけでなく、ビジネス上の要求にも応えます。
- データの信頼性と透明性の担保:
データの出所が明確になることで、経営層やデータ利用部門は、BIレポートや分析結果を「信頼」して意思決定に使えるようになります。 - 監査対応の効率化:
規制当局から「特定の個人情報が、いつ、誰によって、どのように利用されたか」の提出を求められた際、リネージュは客観的な証跡(Audit Trail)として機能します。
現場エンジニアにとっての「障害調査の工数削減」と、経営層や顧客にとっての「データ信頼性の担保」は、表裏一体の課題です。データリネージュの導入を推進する際は、この両面からその価値を説明することが、組織的な合意を得るための鍵となります。
データリネージュの実現する主要な2つの技術アプローチ
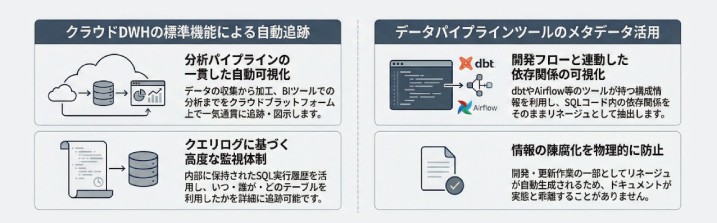
データリネージュの実装において、手作業によるドキュメント作成は、システム変更への追従が困難なため推奨されません。現代のデータ基盤では、既存のツールやクラウド機能を活用した自動的にリネージュが作成されてることが理想となります。
1. クラウドDWHの標準機能による自動追跡:
主要なクラウドプラットフォームでは、データを収集するサービスから、生データの加工やデータマートの作成、BIツールや機械学習などの分析まで一貫して行うことができ、その中でアーキテクト図を自動的に作成する機能など用意されていることが多いです。
また、実行されたSQLクエリの履歴(クエリログ)を内部で保持しているため、いつ誰がどのようなテーブルを利用していたのか、監視体制も優れています。
2. データパイプラインツールのメタデータ活用
dbtやAirflow等のETLツールを使用している場合、ツール自体が持つ構成情報を活用します。
dbtであれば、SQLコード内のFROM句を少しに変更することによってテーブル間の依存関係をそのままリネージュとして可視化することができます。
開発フローの一部としてリネージュが自動更新されるため、情報の陳腐化が発生しません。また、統合機能を活用することで、異なるツール間の情報の集約も容易になります。
データリネージュ機能が備わっているツールのご紹介
データリネージュを実現する最も効果的な方法は、自動化する機能を持った製品を活用することです。特に、データ変換(ETL/ELT)、クラウドDWH、BIの各領域で、リネージュ機能は急速に進化しています。ここでは、データ基盤の運用に直結する主要なツール・サービスを取り上げ、その実現方法を具体的に解説します。
ETL/データパイプラインツールのリネージュ機能
SaaSやオープンソースのリネージュ機能を用いて、管理するアプローチです。ETL/データパイプラインツールは様々な製品がありますが、今回は以下の4つのツールについてご紹介します。
- trocco :
日本発のツールとして直感的なUIに強みがあります。転送設定(ジョブ)を中心に[転送元]→[設定]→[転送先]の関係を可視化でき、リネージュ画面から直接ジョブ編集へ遷移できるなど、運用の利便性が高いのが特徴です。 - Fivetran / Airbyte:
各システムの多様なデータを転送することに特化しており、自前のリネージュ表示よりも外部連携を重視しています。OpenLineage等の標準規格で情報を出力し、dbtやカタログツールで統合管理する高度な構成に向いています。 - Informatica / Talend:
エンタープライズ向けの多様なデータを収集・変換・統合する代表的なETL/データ統合ツールです。データリネージ機能は、テーブルレベルで依存関係を図示することが多いですが、Infomatica / Talendでは、列単位で依存関係まで表現することができます。 - dbt (Transformation特化型):
ELTの「T(変換)」に特化したツールであり、SQL内モデルにて、モデル間の依存関係を自動的に構築します。開発ワークフローそのものがリネージュを生成するため、情報の陳腐化が起きません。
主要クラウドDWHの標準機能(GCP / Azure / AWS)
主要なクラウドプラットフォームは、自社のデータサービス群を横断してリネージュを自動追跡する、強力なデータガバナンス機能を提供しています。
AWS (Glue / DataZone) :
AWS環境での開発を中心とする場合に親和性が高いサービスです。「AWS Glue Data Catalog」はETL処理の入出力を自動記録するエンジニア向けの機能ですが、近年登場した「Amazon DataZone」により、ビジネス用語と紐付けたガバナンス管理も可能になりました。RedshiftなどAWS主要サービス間のデータの流れを統合的に管理できます。
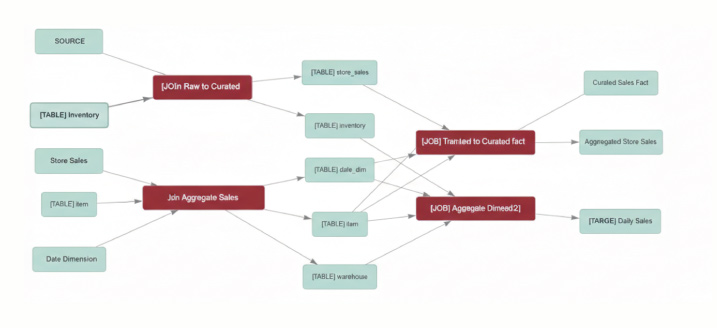
Azure (Microsoft Purview) :
MicrosoftPurviewは、PowerBIレポート上のグラフから元データのデータベースまでをエンドツーエンドで追跡できるため、経営層や利用部門への説明責任を果たすのに適しています。また、AzureだけでなくAWSやオンプレミス環境のデータもスキャン対象にできるなど、統合的なガバナンスプラットフォームとして機能します。
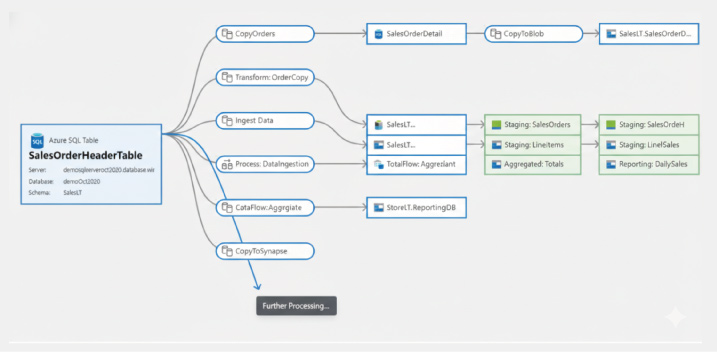
GCP (Data Catalog)
BigQueryを中心としたGoogle Cloudエコシステムに特化しています。BigQueryの管理画面内にリネージタブが統合されており、クエリを実行するだけで自動的にグラフが描画されるなど、導入のハードルが低いのが特徴です。BigQueryだけでなく、Cloud Composer やDataflowなどのETLサービスの処理も自動検知し、データレイクハウス全体の可視化をサポートします。
データリネージュ活用 3つのポイント
データリネージは「導入して終わり」ではなく、「いかに日々の業務フローに組み込むか」が成功の鍵です。ツールを入れたものの、「誰も見ない」「情報が古くて信用できない」となってしまう失敗ケースを避けるための、3つの重要なポイントを解説します。
1. まずはスモールスタートで始めて見る
組織内のすべてのデータリネージを最初から完璧に可視化しようとすると、情報過多で本来見るべきパスが埋もれてしまいます。「経営レポート」や「顧客への請求データ」など、絶対に間違えてはいけない重要なアウトプット(出口)を特定し、そこから逆算して重要なパイプラインを重点的に管理するアプローチが効果的です。
2. 見る人によって「粒度」を切り替える
リネージには「テーブルレベル(大まかな流れ)」と「カラムレベル(列単位の細かい計算)」があります。
ビジネス職や管理職の方は、「この売上データは、どのシステムから来た?」など、算出しているテーブルの原資の在処を機になることが多く、細かいロジックなどまで把握することがないため、テーブルレベルでリネージュできていると良いです。
また、エンジニアの場合は、「このカラムの計算ロジックが変更されたらどこが壊れる?」など具体的な障害の把握が必要になるため、カラムレベルまでリネージュできていると理想です。
3. 自動化を優先し、手動運用は最小化する設計にする
リネージの「鮮度」を保つため、SQL解析やログ連携によってシステム的なつながり(構造)は自動生成することを原則とします。
その上で、自動検知できないアナログなデータの移動や、ビジネス上の意味付け(オーナー情報など)といった「補足情報」のみを手動で管理するという割り切りが重要です。
すべてを手動で描こうとせず、自動化できる土台の上に人の知見を足していくアプローチが形骸化を防ぎます。
まとめ:データ活用の未来を支える「データリネージュ」の重要性
データリネージは、データ活用が高度化し、システムが複雑になりきってから導入しようとすると、依存関係の解明に膨大なコストがかかり、致命的な手遅れになりかねません。だからこそ、プロジェクトの立ち上げやリプレイスの初期段階から、運用保守体制も含めた設計を行っていくことが極めて重要です。
本記事で紹介したようなETLの設計やAPI連携、DWHの構築を実装するのが「データエンジニア」です。
データサイエンティストやアナリストが安心して分析に集中できるのは、データエンジニアが「データのでどころ」や「加工の経緯」を透明化し、ブラックボックス化を防いでいるからです。技術力で信頼性の高いデータの土台を整備し、データパイプラインという血管を正しく張り巡らせる彼らは、まさに分析プロジェクトの“心臓部”とも言える役割を果たしています。
もし「分析屋」という会社で、データエンジニアのプロフェッショナルとして、私たちと一緒に新たな価値創造に挑戦したいと興味を持っていただけましたら、ぜひ下記サイトからエントリーをお待ちしています。




