
アンサンブル学習は、複数のモデルを組み合わせて1つの学習モデルを構築することで高い予測精度を実現する学習手法です。実際のビジネス現場ではXGBoostやLightGBMなどアンサンブル学習を採用した高精度で信頼性の高いフレームワークを活用することで、実証検証までクイックに行うことが主流となっています。
このようなアンサンブル学習の理解には、機械学習における「予測精度」の理解が不可欠です。本記事では機械学習における予測精度から、アンサンブル学習の種類および実際のビジネス現場におけるアンサンブル学習の立ち位置について、当社の機械学習担当者が徹底解説します。
アンサンブル学習は実際のビジネス現場でよく使われる手法ですので、本記事を通してより理解を深めましょう。
アンサンブル学習とは?

アンサンブル学習(Ensemble Learning)は、複数のモデル(弱学習器)を組み合わせて1つの学習モデルを構築することで高い予測精度を実現する学習手法です。アンサンブル(Ensemble)は合奏や合唱を意味する単語であり、調和のとれた集合体を意味します。
”三人寄れば文殊の知恵”ということわざがあるように、1人で問題を解くよりも複数人で意見を出し合って知識を補い合いながら解いた方が、優れた知恵やアイディアが生まれるという考え方を機械学習に取り入れたのがアンサンブル学習です。
アンサンブル学習の必要性
機械学習の入門書などでよく目にする重回帰分析や決定木ですが、実務においてこれらのモデルを単独で使用することはほとんどないでしょう。実務で解くべきビジネス課題は複雑であり、シンプルなロジックのモデルのみでは、入力と出力の関係性をモデルが学習しきれず、必要な予測精度を得られないことが多いからです。
このようなことから、ビジネスの現場ではアンサンブル学習を用いたモデル構築が基本になっています。といっても自前でモデルを複数組み合わせるのではなく、アンサンブル学習のロジックが内部に組み込まれたフレームワークであるXGBoostやLightGBMなどを活用し、スモールデータセットでクイックに実装して検証~改善を行い、プロダクトへの適用可否を判断することが主流となっています。
アンサンブル学習で用いるモデル
アンサンブル学習で用いるモデルは弱学習器である必要があります。弱学習器とは、単独では精度が低い学習器のことであり、ランダムより少し精度の高いモデルです。これら弱学習器の結果に対して多数決や平均をとり、最終的な結果とします。そのため、それぞれのモデルの相関が少ないほうが高精度になります。完全に相関したモデルでは同じ結果を複数出すだけになってしまうからです。
精度向上を目的とした手法であるアンサンブル学習ですが、精度には「バイアス(Bias)」と「バリアンス(Variance)」とよばれる指標があります。まずはこれらの指標について解説します。
予測精度を向上させるとはなにか?
機械学習では様々な特徴量(予測に用いる情報)を用いて実際の値を予測します。したがって、予測精度を向上させるとは「予測値」と「実際の値」との差を最小化することです。このとき、実際の値に対して予測値がどのように分布するかを示す指標として、「バイアス」と「バリアンス」が用いられます。これらは統計学の用語であり、日本語ではそれぞれ「偏り」と「ばらつき(散らばり、分散)」と表現できます。
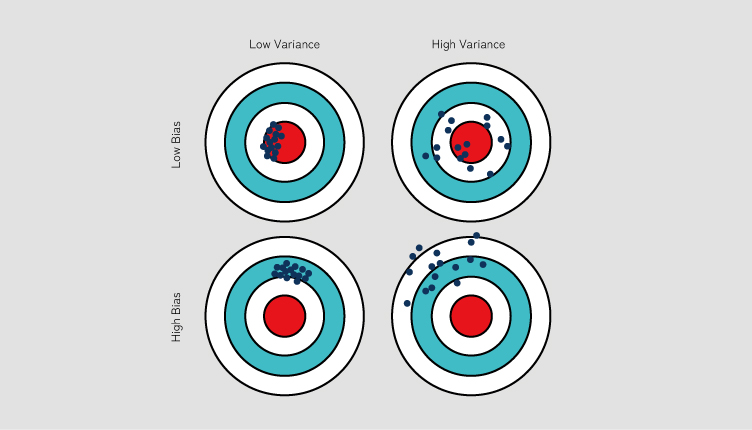
バイアス(Bias):偏り
バイアスは予測値が実際の値から一定方向にずれてしまうことを指します。値が小さいほど実際の値と予測値のずれが小さくなります。バイアスが高い場合、モデルは学習データからしっかりと学習を行えておらず、正しい予測ができない状態といえます。
バリアンス(Variance):ばらつき
バリアンスは予測値がどれだけ散らばっているかを示す度合いのことを指します。値が小さいほど予測値の散らばりが小さくなります。バリアンスが高い場合、モデルは「過学習」をしている可能性が高くなります。
過学習とは、モデルが学習データに過剰に適合(学習データのノイズや偶然の変動まで学習)した結果、学習データに対する予測精度は高いものの、未知のデータに対する予測精度が低下した状態になることです。この状態を汎化性能が低いと表現するため、過学習とは汎化性能が低下した状態といえます。
バイアスとバリアンスはトレードオフの関係
ここで重要なのが「バイアスとバリアンスはトレードオフの関係にある」ということです。
例えば、バイアスが低い場合は実際の値に近い値を正しく予測できている反面、バリアンスは高まり過学習に陥るケースがあります。したがって未知のデータに対しては正しく予測できない可能性が高まります。
バリアンスが低い場合は未知のデータにも対応できる反面、バイアスが高まり実際の値とはかけはなれた予測を行う可能性が高まります。
したがって、バイアスとバリアンスのバランスを適切に調整することでモデルの予測精度を向上させます。とくにバリアンスが高い場合におこる過学習を回避する手段の一つとして、アンサンブル学習があります。
アンサンブル学習の種類
アンサンブル学習は、弱学習器の学習の仕方によって並列学習と逐次学習の2つに分類されます。
加えて、一般的に使われるアンサンブル学習には3つの種類があります。それぞれの特徴を見ていきましょう。
バギング(Bagging)
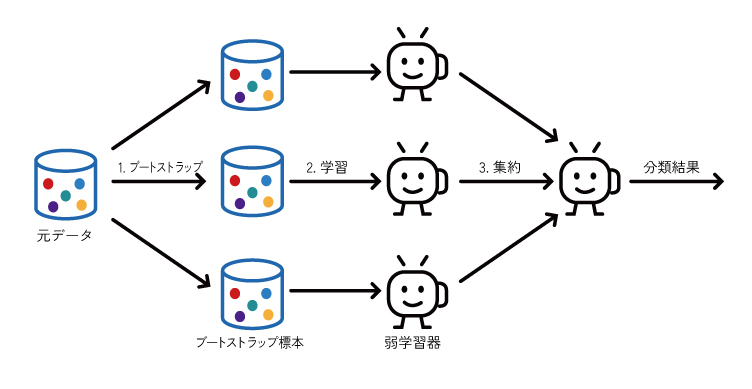
バギングは「ブートストラップ集約法(Bootstrap Aggregating)」の略称で、重複あり(ブートストラップ法)の学習データを作成し、並列(独立)処理でモデル作成を行う手法です。バギングはバリアンスを小さくすることができます。
ブートストラップ法は統計手法の一つです。機械学習においては、与えられた学習データセットから復元抽出を繰り返して複数の新しいサブサンプルを作成し、それらのサブサンプルを使って学習器が学習を行います。復元抽出とは、元となるデータセットから重複を許してランダムにデータを抽出する方法です。これにより、サブサンプルに多様性が生まれることでバリアンス低下につなげています。
ランダムフォレストはバギングの一種で、決定木を弱学習器として複数組み合わせることでアンサンブル学習したものです。ランダムフォレストの特徴としては、弱学習器に投入する特徴量もランダムサンプリングする点です。これによりサブサンプルにさらなる多様性が生まれます。
ブースティング (Boosting)
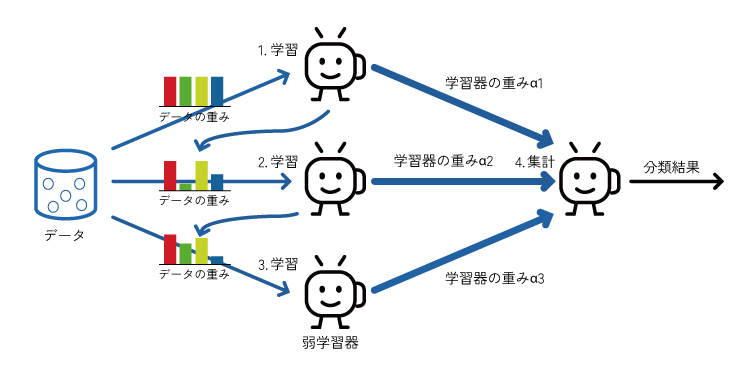
ブースティングは「増強する」という意味を持ちますが、機械学習では過去の学習において誤分類されたデータを重点的に学習し、直列(逐次)処理でモデル作成を行う手法です。ブースティングはバギングと異なりバイアスを小さくすることができます。
ブースティングは、弱学習器を使うため最初の学習で誤った予測を行いますが、次の学習では誤分類したデータの重みを増やして学習することでその誤りを修正します。これを繰り返すことで精度向上を図り、最終的には精度の高いモデルに重みを付けて最終的なモデルを作成します。
ブースティングの代表例としてはXGBoostやLightGBMがあります。これらは勾配ブースティング決定木(決定木とブースティングを組み合わせた手法)を利用しています。とくに、前の学習の誤りを修正する際に勾配降下法を利用しているのでこのような呼び名になっています。XGBoostやLightGBMは高速でかつ高精度なのでKaggleや実務でよく使用されます。
スタッキング (Stacking)
スタッキングは、異なる種類のモデルを組み合わせて最適な予測を行う手法 です。うまく使うことでバイアスとバリアンス両方を低下させることができます。
スタッキングでは、はじめに異なる種類の学習器(SVM・ランダムフォレスト・XGBoostなど)で学習を行います。次に、各モデルの予測結果を特徴量として、新しい学習器(メタモデル)で学習を行うことを繰り返し、最終的な予測結果とします。
簡単なものでは2段階ですが、より複雑に積み上げることも可能です。例えば、KDD cup 2015年で優勝したJeong Yoon Lee氏のスタッキング活用事例では64のモデルをスタッキングさせています。
アンサンブル学習のメリット
精度向上
複数のモデルを組み合わせることで、単独のモデルよりも高い予測精度を実現できます。それぞれのモデルが捉えた異なる特徴を利用し、それらの予測結果を組み合わせることでより正確な予測が可能となります。
汎用性向上
異なるモデルを組み合わせることで、様々なデータに対応可能な汎用性の高いモデルを構築できます。
アンサンブル学習のデメリット
計算コストの増加
アンサンブル学習では複数のモデルを組み合わせるため、単一のモデルを使用するよりも多くの計算コストが必要になります。当然、組み合わせるモデルの数が多くなればより多くの計算コストが必要になります。
実際のビジネス現場では使用可能な計算リソースと、それによって得られるビジネスインパクトを検討してプロジェクトを推進していく必要があります。
過学習の可能性
モデルが複雑になるほどバリアンスが大きくなり、過学習になる可能性が高まります。交差検証(クロスバリデーション)を行うことで過学習を抑制することができますが、盲信せずにモデルの学習状態を正しく評価することが大切です。
解釈性の低下
複数のモデルを組み合わせることで、モデルの解釈性が低下する場合があります。
解釈性とは、モデルやアルゴリズムが出した結果に対する理解のしやすさといえます。これは結論や予測がどのようなプロセスで導かれたのかを人間が理解できる度合いです。アンサンブル学習によって複数のモデルが組み合わさると、各モデルが何を根拠になぜそのような予測を行ったのかわからないことが多く、”解釈性が低い”状態になります。
解釈性が高いモデルやアルゴリズムは、その結果をもとに適切な判断や行動をすることができるため、ビジネスの現場では好まれます。一方で、解釈性が低いモデルやアルゴリズムは、その結果を信じることができず、誤った判断や行動を招く可能性があります。
実務におけるアンサンブル学習

近年ではアンサンブル学習のひとつである勾配ブースティングを採用した高精度で信頼性の高いフレームワーク(XGBoostやLightGBMなど)が普及しており、実際のビジネス現場ではこれらを活用したモデル構築を行うことが一般的です。とくにXGBoostやLightGBMなどの決定木ベースのモデル(勾配ブースティング決定木)では、特徴量が予測にどれだけ寄与しているのかを示す指標である寄与度(重要度:importance)を算出することが可能です。これにより、どの特徴量が予測に最も影響を与えているかを理解することができ、モデルの解釈性が向上します。
また実際のビジネス現場において、k近傍法とXGBoostを組み合わせるといった複雑なアンサンブル学習を行うことは一般的ではありません。Kaggleなどのコンペティションでは精度を最大限に高めることが目的のため複雑なアンサンブル学習を行うことがある一方で、実務ではビジネス課題の解決が目的となります。精度を高めるために費やすコストとそれにより得られるビジネスインパクトを天秤にかけた際に、コストパフォーマンスが悪いと判断されることが多いからです。そのため、精度を上げる上では新たな特徴量を作り出す特徴量エンジニアリングや、ハイパーパラメータとよばれる変数を調整してチューニングすることが多いです。
アンサンブル学習の使用例
アンサンブル学習は、さまざまな分野で活用されています。
金融分野
金融分野では、信用リスクの評価や不正検知、株価や為替レートの予測に利用されています。
とくに金融市場は複雑な動きをすることがら単一のモデルでは十分な精度を出すことが難しいため、アンサンブル学習が適しているとされています。
医療分野
医療分野では、疾患の予測に活用されています。また、画像認識や自然言語処理などの分野でも、アンサンブル学習は重要な役割を果たしています。
アンサンブル学習は、医療分野においても活用されています。複数のモデルを組み合わせることで、患者ごとの疾患の予測精度を向上させることができます。
まとめ
アンサンブル学習は、複数のモデルを組み合わせて高い予測精度を実現する学習手法です。一般的に使われるアンサンブル学習の種類としては、バギングやブースティング、スタッキングがあります。実際のビジネス現場では、バギングの一種であるランダムフォレストや、ブースティングの一種であるXGBoostやLightGBMなどのフレームワークを活用し、実証検証までクイックに行うことが多いです。
分析屋では、未経験からでも活躍できる機械学習エンジニアを育てられるよう教育やキャリアパスの支援に力を入れています。ハードスキル+ソフトスキル(おもてなし精神)の獲得を通して、顧客の本質的なニーズに応えることのできるエンジニアになることで、市場価値の向上や年収アップを目指していくことができます。
機械学習エンジニアとしてのキャリアを築きたい方は、ぜひ分析屋の採用ページをご覧ください。
▼採用サイトはこちら
分析屋採用サイト




