
現代のビジネスや研究において、データから価値ある知見を引き出す機械学習は不可欠な技術となっています。その中でも「分類(Classification)」は、最も基本的かつ強力なタスクの一つです。この記事では、機械学習の「分類」について、その基礎的な定義から、分類の種類、そして実務で頻繁に利用される代表的なアルゴリズムまで、分析屋の現役機械学習エンジニアが体系的に整理して徹底解説します。
1. はじめに:機械学習における「分類」とは?

「分類」の基本的な定義
機械学習における「分類」とは、入力されたデータが、事前に定義された複数のカテゴリ(クラス)のうち、どれに属するかを予測・識別するタスクです 。これは、コンピュータに「仕分け」のルールを教え込むプロセスと考えることができます。
このタスクは、機械学習の大きな枠組みの中で「教師あり学習」という分野に位置づけられます。教師あり学習とは、あらかじめ「正解ラベル」が付けられたデータセット(教師データ)を用いてモデルを学習させ、その学習結果を基に未知のデータに対する予測能力を獲得する手法です。
機械学習には他にも「教師なし学習」や「深層学習(ディープラーニング)」という分野があります。
教師なし学習とは、正解データ(ラベル)を与えずに、データそのものに隠されたパターンや構造をAIが自ら見つけ出す手法です。まるで、大量の写真をヒントなしに「似ているもの同士」でグループ分けしていくような作業に似ています。
深層学習とは、人間の脳の神経回路網(ニューラルネットワーク)を模倣した技術で、AI(人工知能)を飛躍的に進化させた機械学習の一分野です。先述の教師あり学習や教師なし学習との最大の違いは、学習の「深さ」と特徴量の扱いにあります。簡単に言うと、十分な量のデータを与えれば、コンピュータが人間のように自ら学ぶべきポイントを見つけ出し、非常に高い精度で物事を認識・予測・分類することができます。
より詳しく学びたい方はこちらのリンクからぜひ学びを広げてみてください。
・教師なし学習
>Qiita / 「教師なし学習」をゼロから【機械学習】
・深層学習
>docomo Business / 深層学習(ディープラーニング)とは
回帰(Regression)との違い
機械学習の教師あり学習には、「分類」と並んで「回帰(Regression)」というもう一つの主要なタスクが存在します。この二つの違いを理解することは、機械学習プロジェクトの第一歩として極めて重要です。
先ほど述べた通り、分類では、予測する対象が離散的なカテゴリであるタスクです。「犬か猫か」「スパムメールか否か」「顧客が離反するか否か」といった、質的な答えを求めます。
一方で、回帰とは、予測する対象が連続的な数値であるタスクです。「明日の株価」「製品の売上高」「不動産の価格」といった、量的な答えを求めます。
これらの違いについてはこちらの記事で詳しく解説されているので、参考にしてみてください。
>Qiita / AIの「分類」と「回帰」についてまとめてみた
なぜ「分類」が重要なのか?その価値とは?
分類タスクの真の価値は、単にデータをラベル付けすること以上に、人間の判断を伴う定型的な意思決定プロセスを自動化する点にあります。分類モデルは、膨大なデータの中から人間では捉えきれない複雑なパターンを学習し、高速かつ高精度な判断を下すことができます。
例えば、「不正利用の疑い」という分類結果は、単なるラベルではなく、「取引を一時停止する」という具体的なアクションを誘発します。「顧客離反の可能性高」という分類結果は、「割引クーポンを送付する」といったマーケティング施策のトリガーとなります。このように、分類モデルはビジネスの現場において、受動的な分析ツールではなく、能動的な意思決定エンジンとして機能します。これにより、リスクの未然防止、業務効率の劇的な改善、顧客満足度の向上といった、直接的なビジネス価値を創出するのです。
身近な応用例
分類技術は、すでに私たちの身の回りの至るところで活用されています。
迷惑メールフィルタ
受信したメールの内容や送信元情報を基に、「スパム」か「非スパム」かを分類します。
画像認識
写真に写っている物体が「犬」なのか「猫」なのか、あるいは特定の人物の顔であるかを識別します。
医療診断支援
患者のカルテ情報や検査データを基に、特定の疾患に「罹患している」か「健康である」かを判別し、医師の診断を支援します。
金融不正検知
クレジットカードの利用履歴や場所、金額などから、その取引が「不正利用」か「正常な利用」かをリアルタイムで検知します。
顧客離反予測(チャーン予測)
顧客の利用状況や問い合わせ履歴から、近い将来サービスを「解約する」か「継続する」かを予測し、解約防止策に繋げます。
2. 分類問題の種類
分類問題は、予測対象となるクラスの数やその性質に基づき、いくつかのタイプに大別されます。それぞれの特性を正しく理解することは、タスクに応じた最適なモデル設計や評価指標の選定において極めて重要です。
二値分類 (Binary Classification)
二値分類は、データを「はい」か「いいえ」、「陽性」か「陰性」、「合格」か「不合格」のように、2つの排他的なクラスのいずれかに分類する、最も基本的なタスクです。
例えば、「スパムメールか否か」「顧客が商品を購入するかしないか」「システムに異常があるか正常か」といった、AかBかを判定する問題がこれに該当します。シンプルながら、日常生活やビジネスにおける多くの実用的な問題に応用されています。
多クラス分類 (Multi-class Classification)
多クラス分類は、データを3つ以上のクラスの中から1つに分類する問題です。各クラスは互いに排他的であり、1つのデータは必ずいずれか1つのクラスにのみ属します。
例えば、手書き数字の認識(0から9のいずれか)、動物の画像からその種類(犬、猫、鳥など)を特定する問題、あるいはニュース記事を複数のカテゴリ(政治、経済、スポーツなど)のいずれか一つに分類する問題がこれに該当します。モデルの出力層では、全クラスにわたる確率の総和が1になるよう正規化する「ソフトマックス関数」が一般的に用いられ、最も確率の高いクラスが予測結果として採用されます。
多ラベル分類 (Multi-label Classification)
多ラベル分類は、1つのデータに対して複数のラベルを同時に付与できるタスクです。多クラス分類と異なり、各ラベルは排他的ではなく、1つのデータが複数のカテゴリに属することが許容されます。
例えば、1枚の画像に「犬」「公園」「昼間」といった複数のタグを付ける場合や、ニュース記事に複数のトピックタグ(「経済」「政治」「国際」)を付与するようなケースがこれに当たります。
技術的には、各ラベルの有無を判定する独立した二値分類問題の集合として扱われます。そのため、モデルの出力層では、各ラベルに対して独立に確率を計算する「シグモイド関数」が用いられます。各出力の確率は0から1の範囲を取り、その総和が1になる制約はありません。そして、事前に定めた閾値を超える確率を持つすべてのラベルが予測結果となります。
モデル設計における分類タスクの重要性
これまで見てきたように、多クラス分類と多ラベル分類は、単に「クラスが複数ある」という点で共通しているものの、その性質は大きく異なります。分類問題の種類を正しく特定することは、モデルの性能を最大限に引き出すための第一歩です。解決したい課題がどの分類タスクに該当するのかを初期段階で正確に見極めることが、効果的な機械学習モデルを構築する上で極めて重要となり、本来の目的である課題解決のための意思決定支援につながります。
3.【図解】代表的な分類アルゴリズム8選
分類問題を解くための「道具」であるアルゴリズムは数多く存在します。それぞれに思想や特徴、得意・不得意があり、解決したい課題の性質に応じて適切なものを選択することが、プロジェクト成功の鍵を握ります。
このセクションでは、実務で頻繁に利用される8つの代表的なアルゴリズムを取り上げます。その変遷は、モデルの「解釈のしやすさ」と「予測性能の高さ」という、時に相反する二つの要求の間で進化してきた歴史でもあります。シンプルなモデルから複雑で強力なモデルへと順に見ていくことで、このトレードオフの関係性を体感していきましょう。
3.1. ロジスティック回帰 (Logistic Regression)
概要と特徴
名前に「回帰」と付いていますが、分類タスクで最も基本となるアルゴリズムの一つです 。その仕組みは、入力された特徴量を線形結合し(z=w0+w1x1+w2x2+…)、その結果をシグモイド関数と呼ばれるS字型の曲線を描く関数に通すことで、出力を0から1の間の確率に変換します。この確率が、事前に定めた閾値(通常は0.5)を超えればクラス1、そうでなければクラス0、というように分類を行います 。
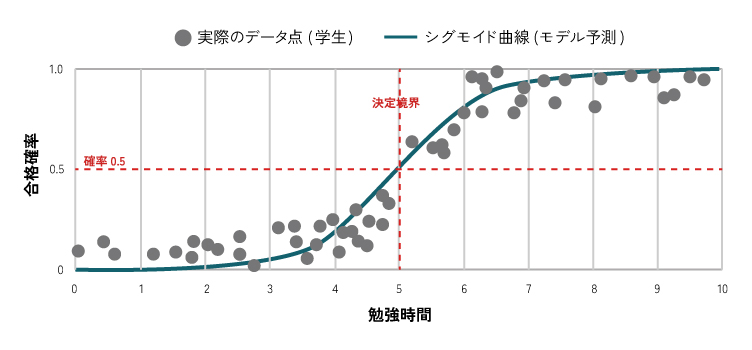
長所(メリット)
・アルゴリズムがシンプルで、計算が非常に高速です。
・モデルの係数(重み)を見ることで、どの特徴量が予測にプラス/マイナスに影響しているかを解釈しやすく、説明性が高いです。
短所(デメリット)
線形分離可能な(直線で分けられる)単純な問題にしか対応できず、複雑な非線形関係を捉えるのは苦手です。
主な用途・得意なケース
スパムメール判定、顧客の購入予測、疾患の有無の予測など、まずはベースラインモデルとして性能を評価するために広く使われます。
3.2. サポートベクターマシン (SVM: Support Vector Machine)
概要と特徴
SVMは、データ点を特徴空間上にプロットし、異なるクラスを最も明確に分離する「境界線(専門的には超平面)」を見つけ出すことで分類を行います。その最大の特徴は、境界線の引き方にあります。SVMは、境界線と各クラスで最も境界線に近いデータ点(これをサポートベクターと呼びます)との距離(これをマージンと呼びます)が最大になるように境界線を決定します。この「マージン最大化」という考え方が、未知のデータに対する高い汎化性能(応用力)を生み出す源泉です。
さらに、「カーネルトリック」という高度な手法を用いることで、一見すると直線では分離不可能な複雑なデータも、高次元の空間に写像して見事に分離することが可能になります。
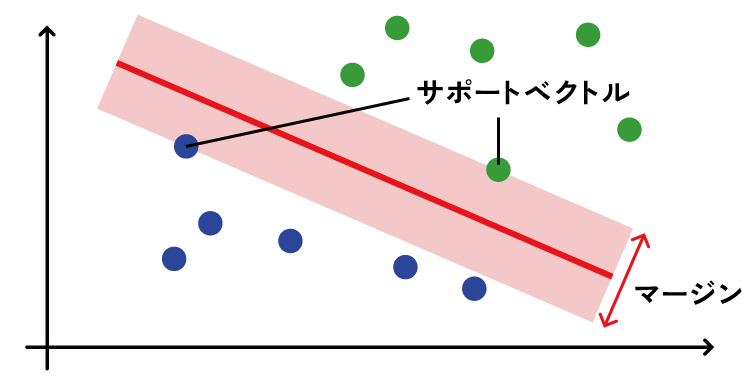
長所(メリット)
・マージン最大化により、未知データに対する高い汎化性能が期待できます。
・特徴量の次元数が高いデータや、比較的データ数が少ない場合でも高い性能を発揮することがあります。
短所(デメリット)
・学習データ量が多くなると、計算コストが非常に高くなる傾向があります。
・適切なカーネル関数の選択や、関連するハイパーパラメータの調整が難しく、勘所が求められることがあります。
主な用途・得意なケース
画像分類、テキスト分類、遺伝子情報解析など、特徴量が多いタスクで強力です。
3.3. 決定木 (Decision Tree)
概要と特徴
決定木は、データに対して「もし特徴量Aが〇〇以上なら右へ、未満なら左へ」といったシンプルな質問(ルール)を繰り返し、データを段階的に分割していく木構造のモデルです。この分岐を繰り返すことで、最終的に各データがどのクラスに属するかを決定します。モデルの構造が人間の意思決定プロセスに非常に似ているため、なぜその予測結果になったのかを視覚的に理解しやすく、解釈性が極めて高いのが最大の特徴です。
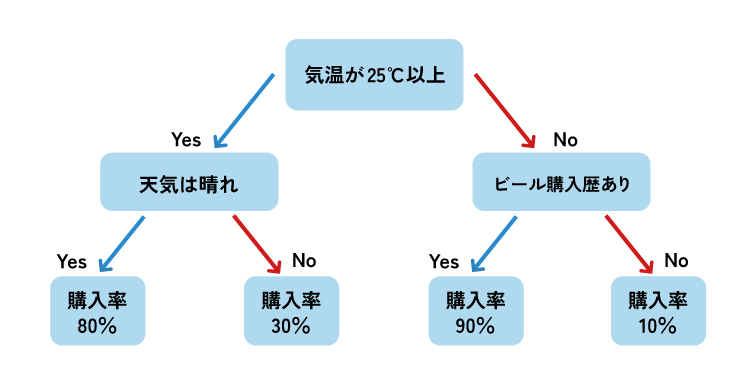
長所(メリット)
・モデルの構造が可視化でき、予測の根拠を直感的に説明できます(高い解釈性)。
・特徴量スケーリングなどの前処理が基本的に不要で、扱いやすいです。
短所(デメリット)
学習データに完璧に適合しようとするあまり、木を深く成長させすぎると、未知のデータに対応できない「過学習」に陥りやすいという大きな弱点があります。
主な用途・得意なケース
金融機関の与信審査、医療診断、顧客分類など、予測結果だけでなく「なぜそうなったのか」という理由の説明がビジネス上、強く求められる場面で重宝されます。
3.4. ランダムフォレスト (Random Forest)
概要と特徴
ランダムフォレストは、決定木の「過学習しやすい」という弱点を克服するために考案された、非常に強力なアンサンブル学習手法の一つです。その名の通り「ランダムな森」を作るように、学習データからランダムに一部のデータ(行)と一部の特徴量(列)を抜き出して、それぞれで少しずつ異なる多数の決定木を独立して作成します。そして、未知のデータを予測する際には、森の中の木々(個々の決定木)にそれぞれ予測させ、その結果を多数決でまとめて最終的な結論とします。
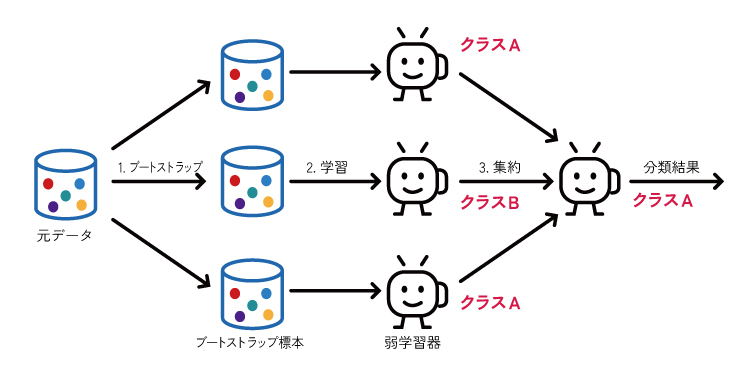
長所(メリット)
・複数の木々の予測を平均化するため、単体の決定木よりも安定して高い精度を発揮し、過学習に対して非常に頑健です。
・ハイパーパラメータの調整に比較的敏感でなく、扱いやすいです。
短所(デメリット)
・多数の木を組み合わせるため、モデルの内部構造が複雑になり、決定木のような高い解釈性は失われます(ブラックボックス化しやすい)。
・学習や予測に要する計算コストが決定木よりも高くなります。
主な用途・得意なケース
顧客セグメンテーション、需要予測、不正検知など、解釈性よりも予測精度が優先される多くの分類タスクで、標準的な選択肢として絶大な人気と信頼を誇ります。
3.5. 勾配ブースティング決定木 (Gradient Boosting Decision Tree)
概要と特徴
決定木をベースにした、非常に強力なアンサンブル学習手法の一つです。ランダムフォレストが複数の決定木を「並列」に作って多数決をとるのに対し、勾配ブースティングは決定木を「直列」に、逐次的に作成していきます。具体的には、まず最初の決定木で予測を行い、その予測と実際の値との誤差(残差)を計算します。次に、その誤差を修正するように2本目の決定木を学習させます。このプロセスを繰り返すことで、モデルは前の木の「間違い」から学び、段階的に全体の予測精度を高めていきます。この誤差を最小化するプロセスには、勾配降下法という最適化アルゴリズムが用いられます。
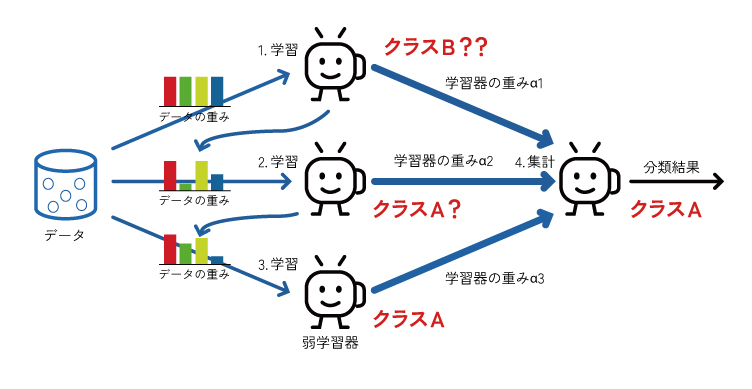
長所(メリット)
・非常に高い予測精度を誇り、多くの分類・回帰タスクで最高レベルの性能を発揮します。
・頑健性が高く、データのノイズや外れ値に対して比較的強いです。
・どの特徴量が予測に重要だったかを評価する機能があります。
短所(デメリット)
・モデルを一つずつ順番に学習させるため、並列計算ができず、学習に時間がかかります。
・非常に高い精度を持つ反面、学習データに適合しすぎて過学習に陥りやすい傾向があります。
・多数の木を組み合わせるため、モデルの内部構造が複雑になり、解釈性は低くなります。
主な用途・得意なケース
・予測精度が最優先される多くの場面で活躍します。金融業界の信用スコアリングやリスク管理、マーケティングにおける顧客の購買予測、そしてKaggleに代表されるデータ分析コンペティションなどで広く採用されています。
・筆者はモデルを作成する際には勾配ブースティング決定木の一種であるLightGBMをベースラインとして実装し、検証を行います。これにより構築から検証までクイックに行うことで、のちに控える意思決定のリードタイムを減らせるよう取り組んでいます。
3.6. k近傍法 (k-NN: k-Nearest Neighbors)
概要と特徴
「朱に交われば赤くなる」ということわざを体現したような、非常に直感的でシンプルなアルゴリズムです 。未知のデータを分類する際、学習済みのデータの中から、特徴空間上で最も距離が近いk個のデータ(近傍点)を探し出します。そして、そのk個のデータの中で最も多数派を占めるクラスを、未知のデータのクラスとして予測します。k-NNは、予測のたびに学習データとの計算を行うため「遅延学習」や「インスタンスベース学習」とも呼ばれます。
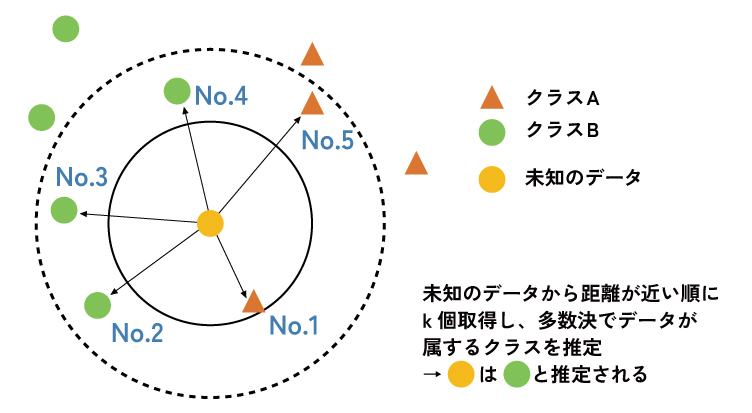
長所(メリット)
・アルゴリズムの考え方が非常にシンプルで、直感的に理解しやすいです 。
・複雑な決定境界を持つデータ分布にも柔軟に対応できます。
短所(デメリット)
・データ数が多くなると、予測のたびに全データとの距離計算が必要になるため、予測速度が著しく低下します。
・各特徴量のスケール(単位や範囲)が異なると距離計算が歪むため、事前のスケーリング(標準化など)がほぼ必須です。
主な用途・得意なケース
パターン認識や小規模なデータセットでのレコメンドシステムなど。アルゴリズムがシンプルなため、手軽に試すベースラインモデルとしても有用です 。
3.7. ナイーブベイズ (Naive Bayes)
概要と特徴
確率論における有名な「ベイズの定理」を分類問題に応用したアルゴリズムです 。その最大の特徴は、計算を単純化するために「各特徴量は互いに独立である(相関がない)」という、非常に大胆で「ナイーブ(単純)」な仮定を置く点にあります。この仮定のおかげで、あるデータが与えられたときに、各クラスに属する事後確率を非常に高速に計算し、最も確率が高いクラスに分類することが可能になります。
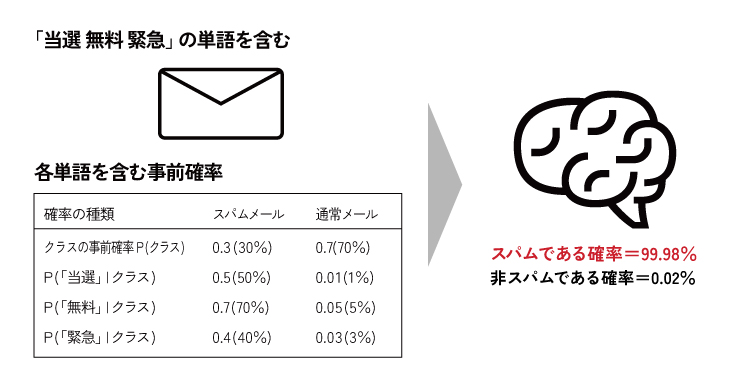
長所(メリット)
・計算が極めて高速で、特徴量の数が非常に多い高次元データや、大規模なデータセットに対しても効率的に動作します 。
・比較的少ない学習データでも、うまく機能することがあります。
短所(デメリット)
「すべての特徴量が独立である」という仮定は、現実世界のデータではほとんど成り立たないため、その影響で精度が頭打ちになることがあります。
主な用途・得意なケース
テキスト分類タスクで伝統的に強力な性能を発揮します。特に、迷惑メールフィルタ、ニュース記事のカテゴリ分類、文書の感情分析などで広く利用されてきました。
3.8. ニューラルネットワーク (Neural Network) / ディープラーニング
概要と特徴
人間の脳を構成する神経細胞(ニューロン)のネットワーク構造にヒントを得た数理モデルです。入力層、複数の中間層(隠れ層)、出力層という複数の層から構成され、各層のニューロンが重み付けされた結合で繋がっています。この層を非常に深くしたものが、現代AIの中核技術であるディープラーニングと呼ばれます。ニューラルネットワークは、その深い階層構造を通じて、データに含まれる極めて複雑で抽象的な非線形パターンを自動で学習する能力に長けています。
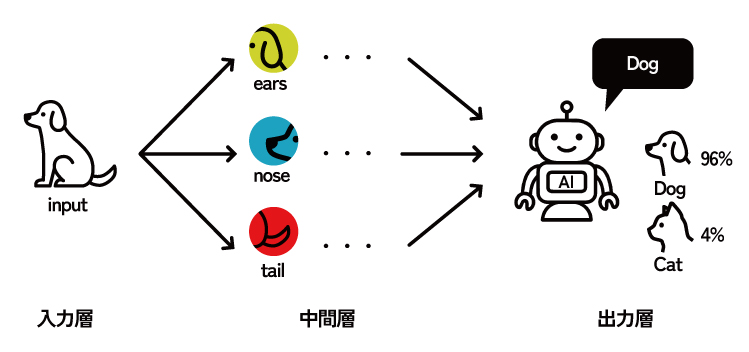
長所(メリット)
・画像、音声、自然言語といった、従来の機械学習アルゴリズムでは扱うのが難しかった複雑な非構造化データに対して、他のアルゴリズムを圧倒する非常に高い予測性能を発揮します。
・特徴量エンジニアリング(人間が有効な特徴量を設計する作業)の手間を大幅に削減できる可能性があります。
短所(デメリット)
・モデルの内部構造が極めて複雑なため、なぜその予測に至ったのかを人間が理解するのは非常に困難で、「ブラックボックス」になりやすいです。
・モデルの学習には、大量のデータと、GPUに代表される高い計算能力(計算リソース)を必要とします。
主な用途・得意なケース
高精度の画像認識、リアルタイム音声認識、機械翻訳、自動運転技術など、現代の最先端AIサービスのほとんどが、この技術を基盤としています。
アルゴリズム選択のための比較一覧表
どのアルゴリズムを選択すべきか迷った際の、クイックリファレンスとしてご活用ください。
| アルゴリズム | モデルの解釈性 | 非線形性への対応 | 過学習のしやすさ | 計算コスト(大規模データ) | 主な強み | 主な注意点 |
|---|---|---|---|---|---|---|
| ロジスティック回帰 | 高 | 不可 | 低 | 低 | 高速・高解釈性 | 線形性の仮定 |
| SVM | 低 | カーネル次第 | 中 | 高 | 高い汎化性能 | パラメータ調整、計算コスト |
| 決定木 | 非常に高い | 可 | 高 | 低 | 非常に高い解釈性 | 過学習しやすい |
| ランダムフォレスト | 低 | 可 | 低 | 中 | 高精度・頑健性 | 解釈性の低下 |
| 勾配ブースティング決定木 | 低 | 可 | 高 | 高 | 非常に高い予測精度 | 過学習リスク、計算コスト、解釈性の低下 |
| k-NN | 中 | 可 | 中 | 非常に高い | 直感的・シンプル | スケーリング必須、予測が遅い |
| ナイーブベイズ | 中 | 不可 | 低 | 非常に低い | 超高速、高次元データに強い | 特徴量の独立性の仮定 |
| ニューラルネットワーク | 非常に低い | 非常に得意 | 高 | 非常に高い | 圧倒的な表現力・性能 | ブラックボックス、大量のデータ/計算資源が必要 |
4. まとめ
本記事では、機械学習における根幹タスクである「分類」について、その基本概念と代表的なアルゴリズムを体系的に解説しました。
分類の基礎:分類がカテゴリを予測する教師あり学習タスクであること、そして数値予測を行う回帰との違いを明確にしました。
分類問題の種類:二値分類、多クラス分類、多ラベル分類について触れ、解決したい課題がどの分類タスクに該当するのかを正確に見極めることが、課題解決のための機械学習において重要となることを紹介しました。
代表的なアルゴリズム:シンプルなロジスティック回帰から、SVM、決定木、そしてアンサンブル学習の勾配ブースティング決定木やランダムフォレスト、さらにはニューラルネットワークまで、8つの主要なアルゴリズムの考え方、長所・短所を紹介しました。
分析屋では、未経験からでも活躍できる機械学習エンジニアを育てられるよう教育やキャリアパスの支援に力を入れています。ハードスキル+ソフトスキル(おもてなし精神)の獲得を通して、顧客の本質的なニーズに応えることのできるエンジニアになることで、市場価値の向上や年収アップを目指していくことができます。
機械学習エンジニアとしてのキャリアを築きたい方は、ぜひ分析屋の採用ページをご覧ください。
▼採用サイトはこちら
分析屋採用サイト




