
最近、ChatGPTをはじめとするAIのニュースを目にしない日はないほど、私たちの仕事環境は急速に変化していますよね。
その中心にある技術の一つが「自然言語処理(NLP)」です。
「言葉はよく聞くけれど、AIと何が違うの?」
「具体的にどんな技術で、今の自分の仕事や、これからのキャリアにどう活かせるんだろう?」
もしあなたが、今の仕事(システム開発、営業企画、データ分析など)から一歩先に進み、データを使ってビジネスを動かすような「提案できる人材」になりたいと考えているなら、この記事はきっと役に立つはずです。
この記事では、データ分析のプロである私たち「分析屋」が、自然言語処理の基礎から、ビジネス現場でのリアルな活用法、そして最新トレンド、さらには未経験からでも目指せるキャリアパスまで、中学生でもわかるように、かみ砕いて解説します。
読み終わる頃には、自然言語処理を「ただ知っている」状態から、「自分のキャリアとして目指す」ための具体的な道筋が見えているはずです。
自然言語処理(NLP)とは?
まずは結論から。自然言語処理(NLP=Natural Language Processing)とは、私たちが日常的に使っている「話し言葉」や「書き言葉」(=自然言語)を、コンピューターが理解できるように処理する技術のことです。
人間の「言葉」をコンピューターが理解する技術
コンピューターは本来、「0」と「1」の数字の世界で動いています。そのため、私たちが使う「おはよう」「ありがとう」といった曖昧(あいまい)で文脈によって意味が変わる「言葉」をそのまま理解することはできません。
自然言語処理は、この「人間の言葉」と「コンピューターの言葉」の橋渡し役だとイメージしてください。この技術のおかげで、コンピューターは言葉の意味を理解し、文章を要約したり、質問に答えたり、翻訳したりできるようになりました。
AI・機械学習・LLMとの違い、そして「なぜ急に賢くなったのか?」
「AIとか、機械学習とか、最近はLLMとか…何が違うの?」と混乱してしまうかもしれませんね。
ここで交通整理をしておきましょう。これらは、実は親子のような関係になっています。
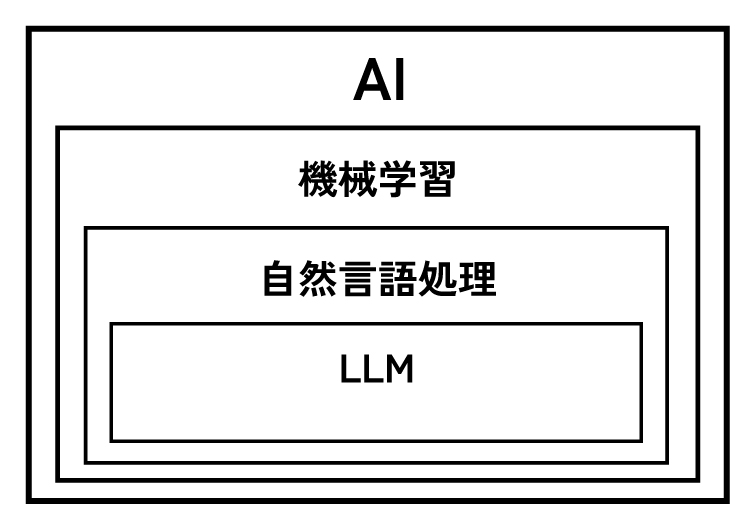
● AI(人工知能):
一番大きな枠組みです。「人間の知能をコンピューターで再現しよう」という大きな目標や分野全体を指します。
● 機械学習:
AIを実現するための「手法」の一つです。コンピューターが大量のデータ(お手本)から自動で学習し、ルールやパターンを見つけ出す技術です。
● 自然言語処理(NLP):
機械学習という手法を使って、「人間の言葉」を扱うことに特化した分野です。
● 大規模言語モデル(LLM):
自然言語処理の中でも、特にインターネット上の膨大なテキストデータを学習させた、超高性能なモデル(AI)のことです。ChatGPTなどがこれにあたります。
AIという大きな家族の中に、機械学習という親がいて、その子供が自然言語処理、そしてその中でも特に大きく成長したのがLLM、と考えると分かりやすいでしょう。
では、なぜここ数年で、ChatGPTのように「急に賢く」なったのでしょうか?
それには、3つの大きな技術的ブレイクスルーがありました。
- 「深層学習(ディープラーニング)」の本格化
以前は、人間が「この単語が来たら、こう返す」といったルールを細かく教えていました(ルールベース)。しかし、人間の脳神経をヒントにした「深層学習」という技術により、AIが自らデータから文脈やパターンを学ぶようになり、性能が大きく向上しました。 - 「Transformer(トランスフォーマー)」モデルの登場
2017年に登場したこの技術が、革命を起こしました。それまでのAIは、文章を「私は」「昨日…」と頭から順番にしか読めませんでした。しかしTransformerは、文章全体の単語の「関連性(どの単語がどの単語に一番強く関係しているか)」を一気に把握できます。これにより、文章の「文脈」を深く理解できるようになり、翻訳や要約の精度が飛躍的に向上しました。 - 圧倒的な「データ量」と「計算パワー」
上記の高性能なモデルを動かすには、教科書となる膨大なテキストデータ(インターネット上の全情報など)と、それを処理するための超強力な計算能力(GPUなど)が必要です。この両方が揃ったことで、AIは一気に賢くなったのです。
これら3つが組み合わさった結果が、現在の「大規模言語モデル(LLM)」であり、私たちが目にする自然言語処理の急速な進化に繋がっています。
自然言語処理を支える4つの仕組み
では、コンピューターはどうやって「言葉」を理解しているのでしょうか?
ここでは、自然言語処理が言葉を解析する代表的な4つのステップ(仕組み)を、ハンバーガーを作る流れに例えて簡単に紹介します。
形態素解析:文章を最小単位の「単語」に分解する
まずは「材料の仕入れと下ごしらえ」です。
「私は昨日おいしいハンバーガーを食べた」という文章があったら、コンピューターはまず、これを意味のある最小単位(単語)に分解します。
「私」「は」「昨日」「おいしい」「ハンバーガー」「を」「食べ」「た」
このように、文章を単語のブロックに分ける作業が「形態素解析」です。これができないと、どこからどこまでが「一つの言葉」なのか分かりません。
構文解析:単語間の関係性(主語・述語など)を明らかにする
次は「材料の組み立て」です。
分解した単語(材料)を並べ、「どれが主語で、どれが述語か?」「どの言葉がどの言葉を説明しているか?」といった**文の構造(骨組み)**を明らかにします。
- (「私」が)→(「食べた」)
- (「食べた」)→(「ハンバーガー」を)
- (「ハンバーガー」は)←(「おいしい」)
このように、単語同士の関係性を把握するのが「構文解析」です。これが無いと、「私がハンバーガーを食べた」のか「ハンバーガーが私を食べた」のか区別がつきません。
意味解析:単語や文章が持つ「意味」を理解する
次は「味付け」です。
文の構造がわかったら、次はその「意味」を理解します。
例えば「おいしい」という単語は「味が良い」という意味だな、と判断します。
もし「銀行に行く」という文章なら、「銀行」には「お金を扱う建物(bank)」と「川の土手(bank)」の2つの意味がありますが、前後の「行く」という言葉から、これは「お金を扱う建物」の方だな、と判断するのが「意味解析」です。
文脈解析:会話の流れや文脈を考慮して意味を判断する
最後は「提供」です。
単一の文だけでなく、会話全体の流れや、置かれた状況(文脈)を考慮して、最終的な意味を判断します。
Aさん:「ハンバーガー、どうだった?」
Bさん:「あれは、ちょっと…」
この「あれは」が「ハンバーガー」を指していることや、「ちょっと…」が(美味しくなかった)というネガティブな意味を含んでいることを理解するのが「文脈解析」です。
この4つのステップを経て、コンピューターは初めて私たちの言葉を「理解」できるのです。
【コラム】なぜPython? R言語との違いは?
「自然言語処理って、具体的にどうやって動かすの?」と、特にシステム開発の経験(ペルソナ①)がある方は気になるかもしれませんね。
結論から言うと、現在のデータ分析、特にAIや自然言語処理(NLP)の現場では、ほぼ間違いなく「Python(パイソン)」というプログラミング言語が使われています。
R言語との違い
データ分析の世界には「R(アール)」という、もう一つの強力な言語があります。Rはもともと「統計解析」のために生まれた言語で、統計モデリングやグラフ化(可視化)の機能が非常に優れています。
では、なぜNLPの分野ではRではなくPythonなのでしょうか?主な理由は2つあります。
- AI・深層学習ライブラリの圧倒的な充実度
1章で触れた、自然言語処理の急激な進化を支えている「深層学習(ディープラーニング)」の道具箱(GoogleのTensorFlowや、MetaのPyTorch)が、ほぼPythonを前提に開発されています。さらに、ChatGPTのような最新のLLM(大規模言語モデル)を扱うための道具箱(Hugging Face Transformersライブラリなど)もPythonのエコシステム(関連ツール群)が圧倒的に充実しています。統計解析(定量データ)はR、AI開発やNLP(非構造化データ)はPython、という棲み分けが進んでいるのです。 - 汎用性(Webサービスとの連携)
Pythonは、NLPのようなデータ分析だけでなく、Webアプリケーション開発(例:分析結果を表示するダッシュボード作成)や業務自動化など、非常に幅広い分野で使われる「汎用言語」です。
分析モデルを「作って終わり」ではなく、Webサービスや社内システムに「組み込む」ところまでを一貫して行えるため、開発現場で非常に重宝されます。
● Pythonの基礎から学びたい方は、こちらの記事もどうぞ
● R言語とのより詳細な違いを知りたい方はこちらの記事もどうぞ
Pythonによる形態素解析のコード例
例えば、2-1で紹介した「形態素解析(文章を単語に分ける)」も、Pythonを使えば、たった数行のコードで実行できます。
ここでは「Janome(ジャノメ)」という、Python用の日本語形態素解析ライブラリを使った例を見てみましょう。
● Python
| # —————————————————- # Pythonによる形態素解析のコード例 # —————————————————- # Janome(ジャノメ)という道具箱(ライブラリ)を使いますよ、と宣言 from janome.tokenizer import Tokenizer # 道具箱を使えるように準備 t = Tokenizer() # 解析したい文章 text = “私は昨日ハンバーガーを食べた” # 道具箱(t)の「tokenize(単語に分ける)」機能を使って、 # textを解析し、結果を1行ずつ表示する print(f”解析する文章: {text}”) print(“—[解析結果]— for token in t.tokenize(text): print(token) |
▼実行結果
| 解析する文章: 私は昨日ハンバーガーを食べた —[解析結果]— 私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー ハンバーガー 名詞,一般,*,*,*,*,ハンバーガー,ハンバーガー,ハンバーガー を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ |
このように、「ハンバーガー」を一つの単語として認識し、さらに「食べ(動詞)」「た(助動詞)」と、品詞まで自動で分解してくれます。
このようにPythonには強力な道具箱が揃っており、これらを使いこなすことがNLPを仕事にする第一歩となります。
もしあなたがSEなどでプログラミングの基礎(特にPython)をすでにお持ちなら、この分野に飛び込む上で非常に大きなアドバンテージになります。
【身近な例】自然言語処理のビジネス活用事例5選
自然言語処理は、すでに私たちの生活やビジネスに深く浸透しています。
ここでは、あなたがきっと使ったことがある5つの事例を紹介します。
検索エンジン:検索意図を汲み取り、最適な情報を提供
Googleなどで検索するとき、「渋谷 おいしい ランチ」と入力すると、ちゃんと「渋谷にあって」「ランチ営業していて」「評価が高い」お店が出てきますよね。
これは、自然言語処理が「あなたが何を求めているか(検索意図)」を、入力された単語の羅列から汲み取ってくれているおかげです。
機械翻訳:言語の壁を越えたコミュニケーションを実現
一昔前の翻訳サイトは不自然な日本語になりがちでしたが、今のGoogle翻訳やDeepLは、非常に自然な文章を生成します。
これは、2章で説明した「文脈解析」の精度が飛躍的に上がったことで、単語を置き換えるだけでなく、文章全体の流れを汲み取った翻訳ができるようになったからです。
チャットボット:24時間365日の顧客対応を自動化
Webサイトの右下によく出てくる「何かお困りですか?」というチャットウィンドウ。
簡単な質問であれば、24時間365日、AIが自動で回答してくれます。これにより、企業は人件費を削減でき、私たちユーザーは夜中でもすぐに疑問を解決できます。
テキストマイニング:アンケートやSNSから顧客の本音を発掘
これはビジネス活用、特にデータ分析の現場で非常に重要です。
お客様アンケートの「ご意見・ご感想」欄や、X(旧Twitter)上の口コミなど、膨大な「文章データ(テキストデータ)」を集めて分析します。
これにより、「どんな言葉と一緒に『不満』が語られているか」「新商品の『どの機能』が好評なのか」といった、顧客の「生の声(本音)」を見つけ出すことができます。
音声認識AI:スマートスピーカーや議事録作成ツール
「OK, Google」「Hey, Siri」でおなじみのスマートスピーカーも、自然言語処理の塊です。
- 人が話した「音声」を「テキスト」に変換し(音声認識)
- その「テキスト」の意味を理解し(自然言語処理)
- 適切な回答や動作を実行する
という流れで動いています。最近では、会議の音声をリアルタイムで文字起こしし、議事録を自動作成するツールも増えています。
NLPが変えた「データ分析の未来」と「仕事」
ここからは、この自然言語処理(NLP)という技術が、私たちデータ分析のプロの「仕事」をどう変えたのか、という核心的なお話をします。
結論から言うと、NLPは、私たちが掲げるMVV(ミッション・ビジョン・バリュー)を実現するための、非常に強力な武器となっています。もしあなたが「データを使って何かを提案する仕事」に興味があるなら、ここは非常に重要です。
分析対象の拡大:定量データ(数字)から定性データ(言葉)へ
データ分析の守備範囲は、NLPによって圧倒的に広がりました。
これまでのデータ分析は、主に「定量データ(数字)」=「合理」を扱うものでした。例えば、「A商品の売上は月100万円」「B商品のクリック率は5%」といった、カチッとした数字(構造化データ)が中心です。
しかし、自然言語処理の登場により、私たちは「定性データ(言葉)」=「情理」という、これまで扱えなかった膨大な宝の山を分析できるようになりました。
- お客様アンケートの自由記述欄(感謝や不満の「感情」)
- コールセンターに寄せられる問い合わせのログ(「なぜ」困っているかの背景)
- 営業担当者が記録している商談メモ(顧客の「想い」や「事情」)
これらはすべて「言葉」であり、数字(合理)だけでは見えない「理由」や「感情」(情理)が詰まっています。
意思決定支援の深化:「0か100か」ではない、「人間らしい」提案へ
「言葉(情理)」を分析できるようになった結果、私たちの「提案の質」が劇的に変わりました。
従来の定量分析(数字=合理)だけでの判断は、「0か100か」の冷たい意思決定になりがちです。
「A案とB案、どちらが売れたか?」
→「A案です。だからA案を採用しましょう」
これに対し、私たち分析屋が目指すのは「合理と情理の和」です。NLPは、まさにそれを実現してくれました。
「A案とB案、どちらが売れたか?」
→「売上(合理)はA案が上です。しかし、アンケート(情理)を分析すると、『A案はデザインが良いが、機能面で不満』という声が多く、逆に『B案はデザインが惜しいが、機能は絶賛』という声が目立ちました」
この「合理」と「情理」を組み合わせた分析結果から、どんな提案ができるでしょうか?
「0か100か」ではない、「A案のデザインとB案の機能を組み合わせたC案こそが、お客様が本当に望んでいる姿(情理)に応えつつ、売上(合理)も最大化できる可能性が高いです」といった、背景やニュアンスを汲み取った「人間らしさが宿る」意思決定を支援できるようになるのです。
分析屋の強み:「おもてなし分析」による、ビジネス課題の解決
この「定性(言葉・情理)× 定量(数字・合理)」のハイブリッド分析こそが、分析屋のバリューである「おもてなし分析」の真髄です。
私たちは、データを分析して「はい、結果です」と報告するだけの仕事はしません。それは、お客様の課題を本質的に解決したことにならないからです。
私たちが目指すのは、「納得できる」意思決定を「おもてなし」で紡ぎだすデータ分析共創パートナーです。
NLPという武器を手に入れたことで、私たちは数字の裏に隠された「想い」や「事情」(=情理)にまで寄り添い、「では、次に何をすべきか?」を顧客と共に考え、提案し、成功まで伴走することができます。
自然言語処理の「今」と「これから」
自然言語処理の世界は、今この瞬間も猛スピードで進化しています。
「今から学んでも遅くない?」と思うかもしれませんが、むしろ「今」だからこそチャンスです。
ここでは、あなたの未来の仕事に直結する、3つの最新トレンドを紹介します。
① マルチモーダルAI:テキストの壁を超え、画像や音声も同時に理解する
これまでのAIは「テキスト専門」「画像専門」と、得意分野が分かれていました。
しかし、最新のトレンドは「マルチモーダルAI」です。
これは、テキスト(言葉)だけでなく、画像、音声、動画なども同時に理解できるAIです。(例:OpenAIのGPT-4o、GoogleのGemini)
これが「仕事」でどう役立つか?
例えば、会議の「音声(誰が話したか)」と「映像(どんな表情か)」と「テキスト(議事録)」を同時にAIが分析し、「今日の会議で、Aさんは新機能に賛成でしたが、口調や表情から懸念も感じられます」といった、人間でも見逃しがちな深い分析が可能になります。
② RAG(検索拡張生成):AIの「嘘」を防ぎ、最新の社内情報で回答を生成
ChatGPTなどのLLMには、「平気で嘘をつく(ハルシネーション)」、「最新情報を知らない」という大きな弱点があります。
それを解決する技術が「RAG(ラグ)」です。
これは、AIが回答を生成するときに、リアルタイムで外部の信頼できる情報(例:社内の最新マニュアル、今日のニュースなど)を「検索」し、その正確な情報を「根拠」にして回答を生成する仕組みです。
これにより、分析者は、社内の膨大な資料を探し回る単純作業から解放されます。AIが提示した正確な根拠(データ)に基づき、「では、このデータからどんな戦略を立てるか?」という、人間にしかできない、より上流の「提案」活動に集中できるようになるのです。
③ LLMの進化:長文の理解と産業特化
LLM(大規模言語モデル)自体も進化しています。
ポイントは「長文」と「特化」です。
- 長文の理解:一度に処理できる情報量が劇的に増え、数百ページのPDF(契約書や研究論文)や、プロジェクト全体のプログラムコードを丸ごとAIに読み込ませ、「要約して」「問題点を洗い出して」といった指示が可能になりました。
- 産業特化:金融、法務、医療など、専門用語や特有の文脈に最適化された「専門家AI」が次々と生まれています。
これらの進化は、あらゆる業界で「データ分析の専門家」の需要がますます高まっていることを示しています。
自然言語処理を仕事にする3つのキャリアパス
「面白そうだけど、自分でもなれるんだろうか?」
そう思ったあなたへ。自然言語処理を仕事にするキャリアは、様々なバックグラウンドから目指すことができます。
ここでは、まさにあなたが今いるかもしれない場所からスタートする、3つのキャリアパスモデルを紹介します。
モデル1:SE・プログラマーからのキャリアチェンジ
もしあなたが今、システム開発の経験(特にPythonなど)をお持ちなら、それは強力な武器です。
- キャリア:技術力を活かし、分析モデルを開発・実装する「データエンジニア」や「機械学習エンジニア」を目指せます。
- 強み:5章で紹介したRAGのシステム構築や、LLMを活用した社内ツールの開発など、技術的な側面からデータ分析をリードできます。
分析屋では納品して終わりの開発ではなく、「そのシステムがどうビジネスに貢献したか」まで見届け、提案できる環境があります。
モデル2:営業・企画職からのキャリアチェンジ
「プログラミング経験はないけど、今の業界の知識なら誰にも負けない」というあなたも、データ分析の世界で輝けます。
- キャリア:業界知識(ドメイン知識)を活かし「そもそも何を分析すべきか?」という課題を設定し、分析結果から具体的な施策を提案する「データアナリスト」や「データコンサルタント」を目指せます。
- 強み:4章で述べた「解像度の高い提案」は、現場のリアルな感覚があってこそ。経験や勘に頼っていた部分を「データ」で裏付けし、ロジカルにビジネスを動かせます。
分析屋では未経験からスタートした先輩も多数在籍。あなたの業界知識は、私たちが分析する上で最も価値のある「宝」です。
モデル3:データアナリストとしてのスキルアップ
すでにデータ分析に携わっているものの、「依頼されたデータを集計・レポートするだけで、提案まで踏み込めない」と悩んでいませんか?
- キャリア:受動的な分析から脱却し、4-2で解説したような「定性×定量」の分析を武器に、顧客の課題を先回りして解決する「戦略パートナー」としてのキャリアを築けます。
- 強み:あなたが持っている分析スキルを、分析屋の「能動的な提案」のノウハウと掛け合わせることで、あなたの市場価値は一気に高まります。
分析屋では「顧客に言われた通り」ではなく、「顧客のためになること」をデータに基づいてこちらから提案する文化が根付いています。
分析屋で実現するキャリア
私たち分析屋には、これら3つのモデルケースをはじめ、多様なバックグラウンドを持つメンバーが、それぞれの強みを活かして活躍しています。
もし「自分のキャリア、もっと面白くできるかも」と少しでも感じたら、ぜひ一度、私たちの仲間がどんな風に働いているか覗いてみてください。
未経験からスキルを身につけるための学習方法
キャリアチェンジに向けて、今日からできる学習ステップも紹介します。まずは「楽しい」と思えるところから手をつけてみましょう。
おすすめの書籍・オンライン学習サイト
- オンライン学習:まずは動画で全体像を掴むのがおすすめです。「Progate」や「Udemy」には、データ分析の基礎であるPythonの入門コースが豊富にあります。
- 書籍:『スッキリわかるPython入門』などの初心者向けの書籍で、実際に手を動かしながら学ぶ(=写経する)のが近道です。
取得しておきたい関連資格
スキルを客観的に証明するために、資格取得も有効です。
- G検定(ジェネラリスト検定):AI・ディープラーニングの基礎知識を幅広く学べます。「自分はAIやデータのことを理解しています」という共通言語を持つために役立ちます。
- Python 3 エンジニア認定データ分析試験:Pythonを使ったデータ分析の基礎スキルを問う試験です。6章のモデル1(SE)を目指す方には特におすすめです。
まとめ
最後に、この記事の重要なポイントを振り返りましょう。
- 自然言語処理は、人間の「言葉」をコンピューターが理解する技術です。
- この技術は、AIという大きな枠組みの一部であり、「形態素解析」など4つの仕組みで動いています。
- 最大の功績は、分析対象を「数字」から「言葉(定性データ)」へと広げたこと。
- これにより、ビジネスの提案が「0か100か」ではなく、背景や理由に踏み込んだ「解像度の高い」ものに進化しました。
- この力は、当社の「合理と情理の和」を重んじる「おもてなし分析」の哲学と直結しています。
- AIは「マルチモーダル」や「RAG」といった進化を続けており、分析者の仕事は「作業」から「提案」へと、より高度化しています。
- このスキルは、SE、営業・企画、現職分析者など、どんなバックグラウンドからでも目指せる、将来性の高いキャリアです。
自然言語処理の専門性は、あなたのキャリアを切り拓く強力な武器になります。
そして、そのスキルを「誰かの指示通り」ではなく、「ビジネスを動かす提案」のために使いたい。もしあなたがそう考えるなら、私たち分析屋は最高の環境かもしれません。
私たちと一緒に、データと言葉の力でビジネスの未来を提案しませんか?




